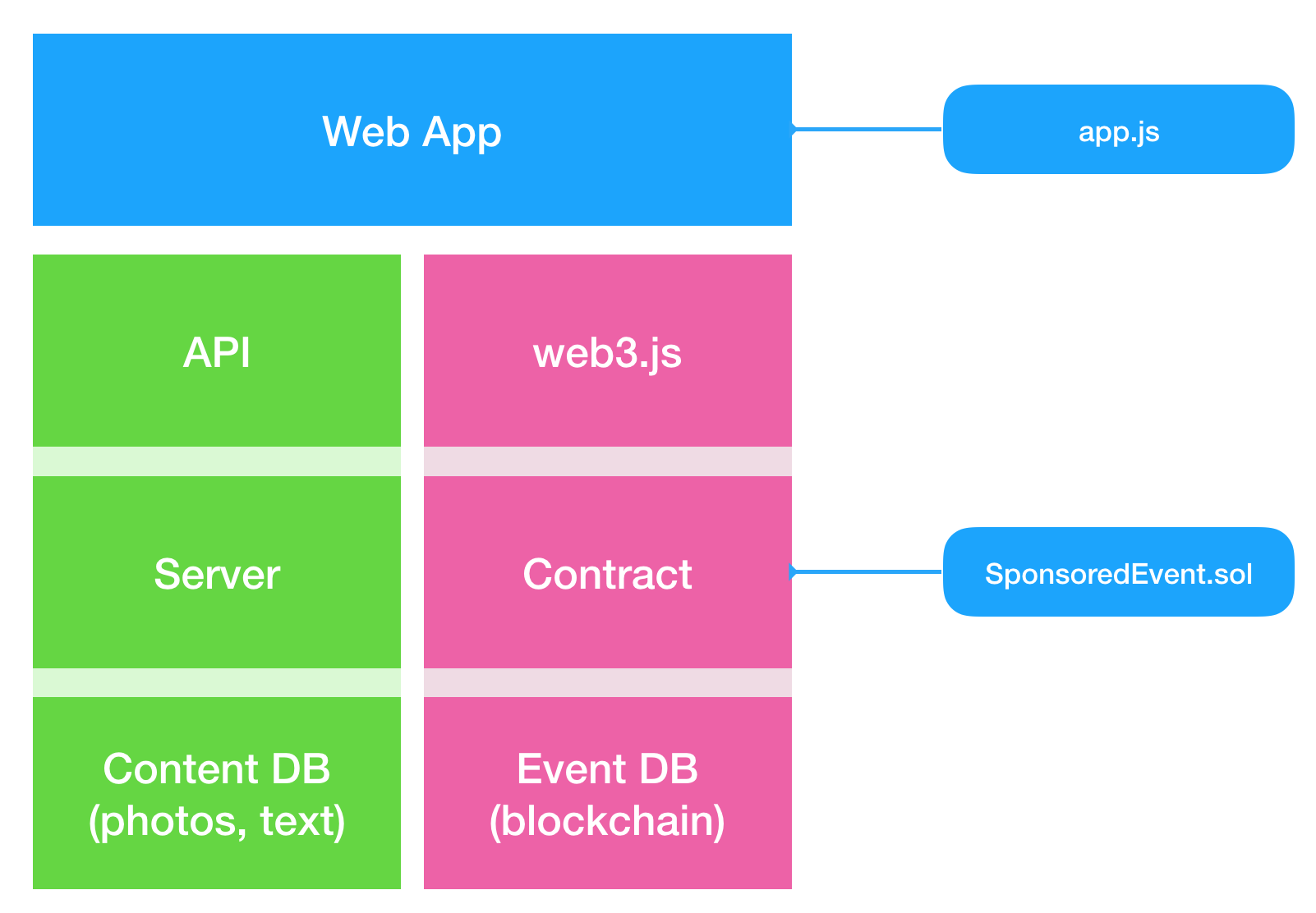
I've been doing a lot of work in Vue recently so when I was asked to evaluate using Web Components on an upcoming project, I approached it with a Vue-ish mindset.
I've not really kept my eye on Web Components for the last couple of years beyond seeing original proposals being superceded and import specs being replaced. Just seeing those things on the periphery were enough to make me think "Meh... I'll have a look later when it's all died down".
Now, I know that Web Components !== Vue. But, I was interested in what knowledge could be migrated from one technology to the other. If I were building an actual web app, I'd definitely use Vue. Building a boxful of reusable, shareable UI elements, though... let's find out.
I'm not going to build anything too complex to start with. How about an "Planet Summary" panel? A simple panel that renders summary information about a planet given a JSON object.
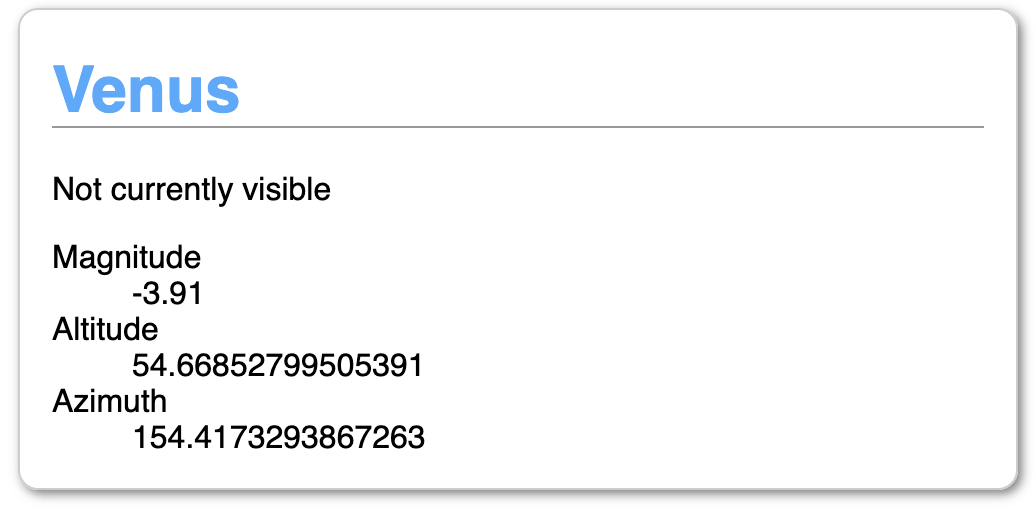
I have an API that returns JSON information about where in the sky to find planets when given your latitude and longitude. For example, if you're standing slightly south of the centre of Berlin and want to know where Venus is, you'd make this request:
https://planets-api.awsm.st/venus/52.5/13.4
And the response would be:
{
"name": "Venus",
"number": 1,
"colour": 1,
"colleft": 24,
"colright": 25,
"alt": 13.043427032890424,
"az": 290.3495756869397,
"dec": 22.661411404345362,
"ra": 110.21545618074397,
"H": 98.18491228623316,
"eclon": 108.59563862950628,
"eclat": 0.5200939814134588,
"illum": 0.9918628383385676,
"r": 0.7192422869900328,
"dist": 1.7155717469739922,
"mag": -3.909377586961354,
"elong": 0,
"pa": 0,
"p": 1,
"description": {
"altitude": "Barely above the horizon",
"azimuth": "West"
},
"visible": false
}
In this case, it determines Venus isn't visible because, even though it's above the horizon, it's not bright enough given the time of day (about 6pm).
We want to make a little UI card that displays this information.
Mapping Vue features to Web Components
| Vue | Web Component | Notes |
|---|---|---|
| name | class name | |
| data | instance properties | |
| props | attributes | these are not reactive by default. Attributes have to be specifically observed (see watch). |
| watch | attributeChangedCallback | first, register your watched attributes with `observedAttributes` then process them in attributeChangedCallback |
| computed | getters | |
| methods | class methods | |
| mounted | connectedCallback | called async so the component may not be fully ready or may have been detached. Use Node.isConnected to protect against calling a dead node |
| componentWillUnmount | disconnectedCallback | |
| style block | style block inside template | styles are scoped by default |
| template block | literal template | JS literal templates (backtick strings) are nowhere near as powerful for templating as an actual template library. Vue template features such as `v-for` can be replicated with vanilla JS but a single-purpose template library (such as `lit-html`) is a good idea. |
NOTE: I am deliberately not using Webpack. I realise that actual applications would be using additional tooling but I want to see what we can do without it.
The first thing that clicked with me was when I realised that computed properties and getters are identical. Nice.
Here's Vue code to return the planet name or a default string:
computed: {
name() {
return this.planet.name || '';
},
}
And Web Component:
get name() {
return this.planet.name || '';
}
Well, that was easy (and trivial).
The same goes for defining the custom element for use in the DOM
Vue:
components: {
"planet-summary": PlanetSummary
}
Web Components:
customElements.define("planet-summary", PlanetSummary);
The only real difference at this level is the data binding. In Vue, props passed from a parent element to a child are automatically updated. If you change the data passed in, the child updates by default. With Web Components, you need to explicitly say you want to be notified of changes.
This is basically the same as setting a watch in Vue. Data that changes in a slightly less tightly-bound fashion can be watched and the changes trigger updates further down.
Watches
Watches in Vue:
watch: {
altitude(newValue, oldValue) {
...
}
}
With Web Components, registering a watch and reacting to changes are separate:
static get observedAttributes() {
return ['altitude'];
}
attributeChangedCallback(name, oldValue, newValue) {
if(name === 'altitude') {
...
}
}
Templating
Vue contains full templating support – for loops, conditional rendering, seamless passing around of data. Natively, you have literal templates and that's about it.
To create a list of planets, you'd use the v-for directive and loop over your planets array.
Vue:
<ul>
<li v-for="planet in planets">
<planet-summary :planet="planet"></planet-summary>
</li>
</ul>
Web Component
<ul>
${this.planets.map(planet => `
<li>
<planet-summary planet='${JSON.stringify(planet)}'></planet-summary>
</li>
`).join('')}
</ul>
The join is there because we're creating an HTML string out of an array of list items. You could also accomplish this with a reduce.
Boilerplate
With Web Components, your component lives in the Shadow DOM so you are responsible for updating it yourself. Vue handles DOM updates for you.
Here is a basic render setup:
constructor() {
super();
this._shadowRoot = this.attachShadow({ mode: "open" });
this.render();
}
render() {
this._shadowRoot.innerHTML = '';
this._shadowRoot.appendChild(this.template().content.cloneNode(true));
}
This needs to be explicitly included in every component as they are standalone whereas Vue automatically handles DOM updates.
CSS
Due to the fact that Web Components live in a separate document fragment, There are complications around sharing styles between the host page and the component which are nicely explained on CSS Tricks. The biggest benefit, on the other hand, is that all styles are scoped by default.
Vue without Webpack (or other tooling) also has its own complications around styles (specifically scoping styles) but if you're building a Vue application, it is much more straightforward to specify which styles are global and which are scoped.
Summary
Here is the Vue Planet Summary and the source of planet-summary-vue.js.
Here is the Web Component Planet Summary and the source of planet-summary.js.
Bonus: here's a Planet List Web Component which includes the Planet Summary component. And the source of planet-list.js
All in all, pretty much everything between basic Vue Components and Web Components can be mapped one-to-one. The differences are all the stuff around the basic construction of the components.
I'd say that if you're looking to build completely standalone, framework-free reusable components, you'll be able to accomplish it with the Web Components standard. You just might have a bit of extra lifting and boilerplate to deal with.
On the other hand, if you're already planning on building a full web application with data management and reactive components, use the tools available to you.