Concept
Another proof-of-concept game design prototype. This is kind of a puzzle game. Ish. It's mostly a simple maze game but one in which you can't see the walls. You can see the goal all the time but you are limited to only being able to see the immediate area and any items lit up by your torch. You control by touching or clicking near the torch. The character will walk towards as long as you hold down. You can move around and it'll follow.
The first 10 levels are very easy and take practically no time at all. After that, they get progressively harder for a while before reaching a limit (somewhere around level 50, I think). The levels are procedurally generated from a pre-determined seed so it would be possible to share high scores on progression or time taken without having to code hundreds of individual levels.
Items that could be found around the maze (but aren't included in this prototype) include:
- Spare torches which can be dropped in an area and left to cast a light
- Entrance/exit swap so that you can retrace your steps to complete the level
- Lightning which displays the entire maze for a few seconds (but removes any dropped torches)
- Maze flips which flip the maze horizontally or vertically to disorient you.
I worked on this for a few months (off and on) and found it to be particularly entertaining with background sound effects of dripping water, shuffling feet with every step, distant thunder rumbling. It can be very atmospheric and archaeological at times.
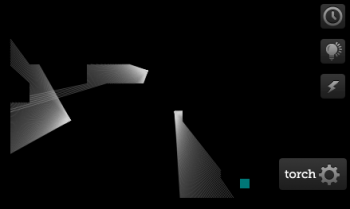
Slightly technical bit
The game loop and draw controls are lifted almost line-for-line from this Opera Dev article on building a simple ray-casting engine. I discarded the main focus of the article - building a 3D first-person view - and used the top-down mini map bit on its own. The rays of light emanating from the torch are actually the rays cast by the engine to determine visible surfaces. It's the same trick as used in Wolfenstein 3D but with fewer uniforms. It's all rendered on a canvas using basic drawing functionality.
The audio is an interesting, complicated and confusing thing. If I were starting again, I'd look at integrating an existing sound manager. In fact, I'd probably use an entire game engine (something like impact.js, most likely) but it was handy to remember how I used to do stuff back in the days when I actually made games for a living. Most of all, I'd recommend not looking too closely at the code and instead focusing on the concept.
Go, make.
As with Knot from my previous blog post, I'm not going to do anything with this concept as I'm about to start a big, new job in a big, new country and I wanted to empty out my ‘To do’ folder. The code's so scrappy, I'm not going to put it up on GitHub along with my other stuff, I seriously do recommend taking the concept on its own. If you are really keen on seeing the original code, it's all unminified on the site so you can just grab it from there.
The usual rules apply, if you make something from it that makes you a huge heap of neverending cash, a credit would be nice and, if you felt generous, you could always buy me a larger TV.



