-
-
Sine
Another game concept prototype – Sine
Honestly, I have no idea what I was going for with this one. It started off last weekend with a vague idea about matching patterns of numbers and old-school graphics and I don't know what and ended up with this.
The idea is to make the bottom row match the top row, basically. There are several front-ends to this game so you can choose the style of play you prefer - numbers and letters, waves, colours or a generated sound wave (if you have a shiny new-fangled browser). It uses the nifty little Riffwave library to generate PCM data and push it into an audio element.
Further development
If I were to develop this further, I'd try and build it in a modular fashion so that front-ends could be generated really easily and open it to other people to see how many different ways this game could be played. It'd be an interesting social experiment to be able to play what is fundamentally the same game in a dozen different ways. You could find out if visual thinkers processed the information faster than numerical or audio-focused people. Leaderboards could allow different styles of player to compete on the same playing field but with a different ball (hmm, weak sports analogy). The rhythms of the game lend themselves well to generated drum tracks so there's probably something in that area for exploring as well.
At the moment, the code is written as the programming equivalent of stream-of-consciousness – global variables everywhere, some camel-case, some underscored, vague comments sprinkled around. There's some commented-out code for the wave mode that moves the waves closer together so that there's a time-limit set but I felt it didn't suit the game.
-
Explanating
I never really marketed it much but I wrote a book called ‘Explanating’ a couple of years ago. I even decided to self-publish1 and organised ISBNs and everything.
The book is an "illustrated collection of completely plausible but entirely untrue explanations of everyday phenomena". Basically, it's lots of the kinds of things you might make up to explain something to a kid if you really have no idea. Hence the name ‘Explanating’ – it's kinda like explaining but not quite right. It also has a rather nice cheesecake recipe in the appendix. I put it on Lulu and Amazon and didn't really do anything else with it. I did try to get it in the iBookstore but that seems to be a horribly complicated process if you aren't based in the US.
Now available for the low, low price of...
Rather than have the book sit around for another few years not doing anything useful, I've decided to try something new. You can now download the book for free from explanating.com in your ebook format of choice (PDF, ePub, Mobi). You don't have to pay anything.
Unless you want to.
If you read it and decide you like it, you can come back to the site any time and buy it from Lulu or Amazon for £1.71 (or the equivalent in USD or EUR or wherever you happen to be). Or not, you could like it and keep it and not pay anything. It's entirely up to you. And your conscience :D.
Download, read, buy
I have no idea if anyone will actually take me up on this offer but I hope some people do, at least, enjoy the book. If nothing else, make the cheesecake, it's delicious.
And that URL once more
-
HighlightBlock.vim
Okay, this'll be my last vim post for a while. I just couldn't leave it alone, though.
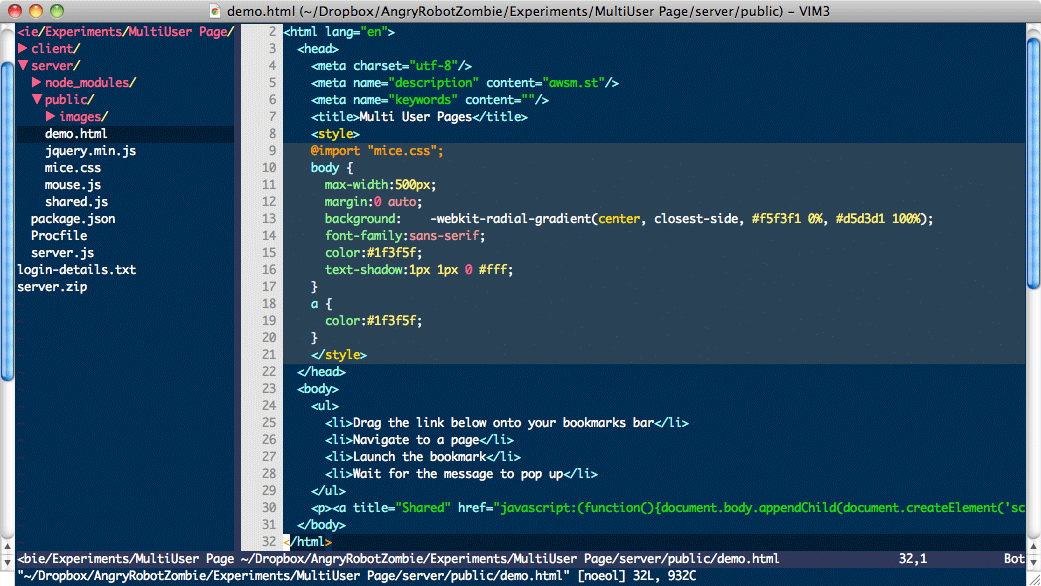
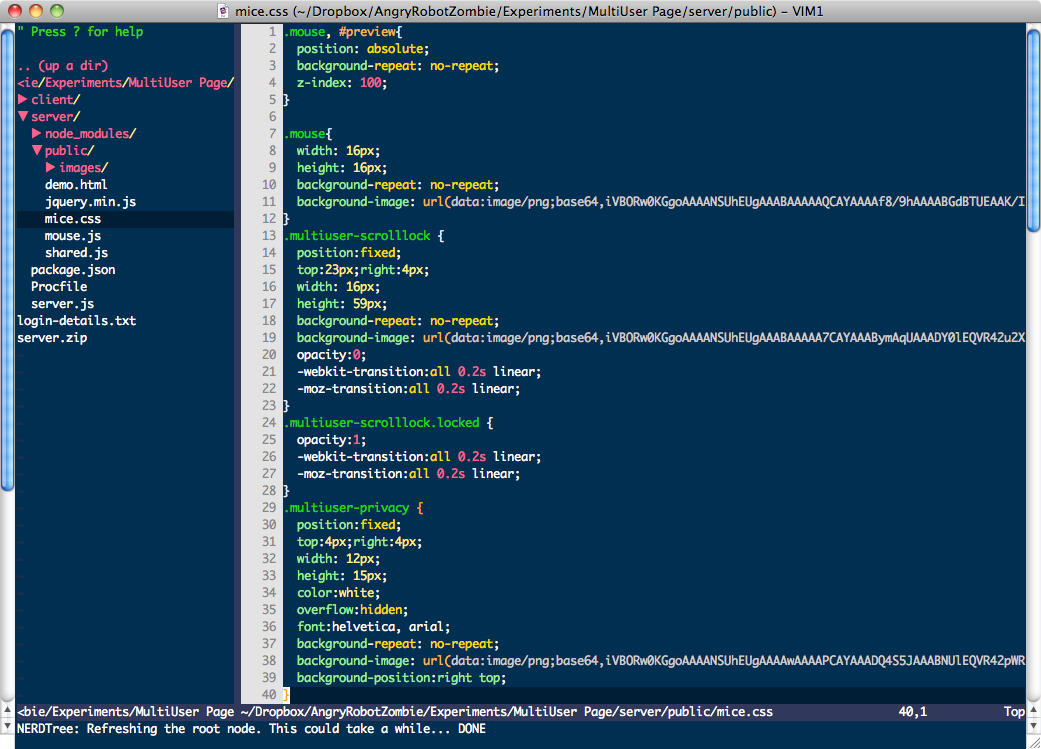
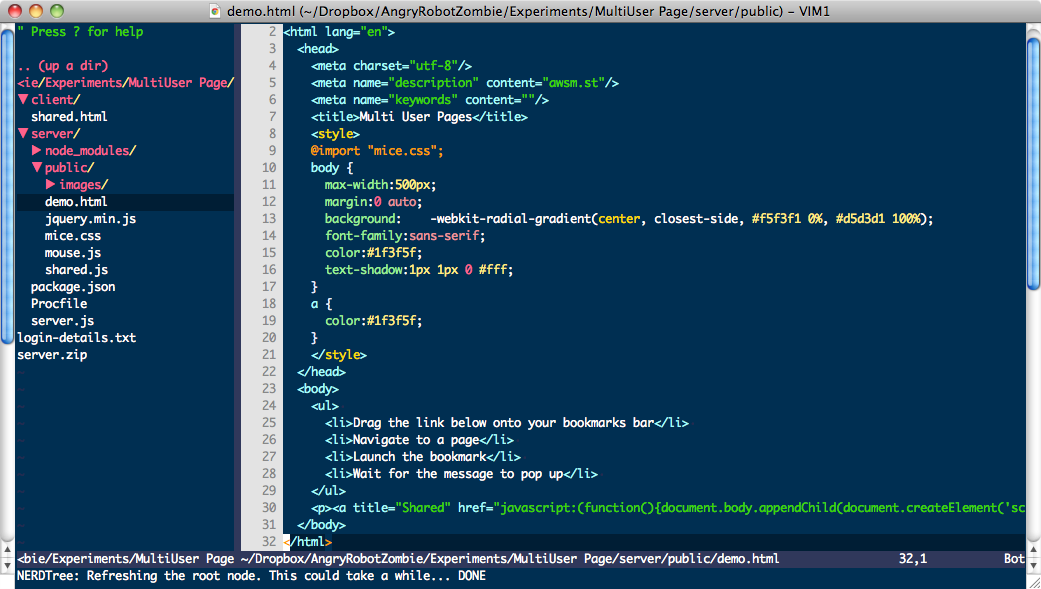
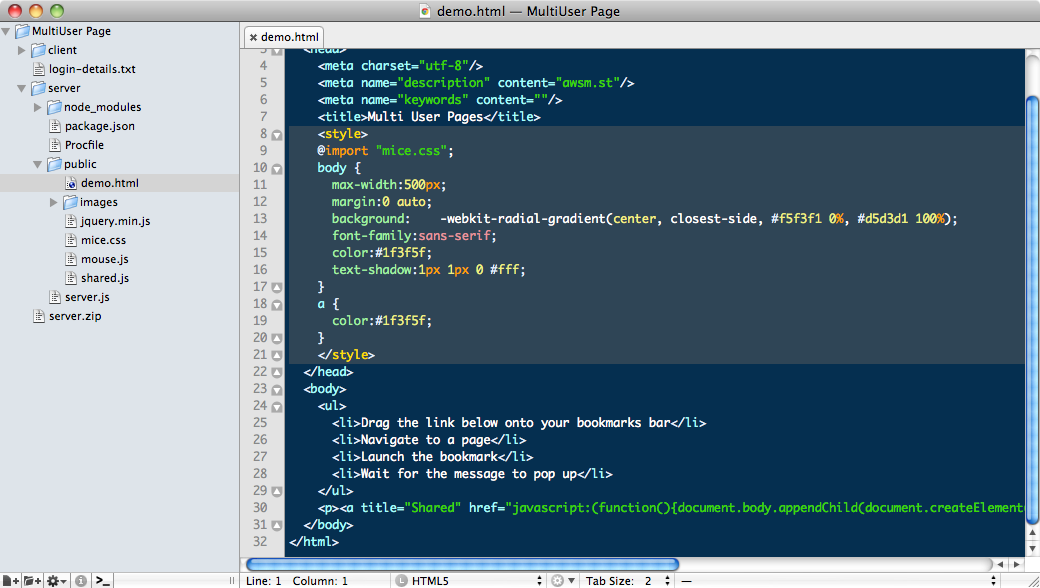
My Cobalt theme was good but it wasn't quite enough. You'll see from the screenshots that the entire HTML page had the same background colour in Vim while the TextMate version changed the background colour inside
<style>and<script>blocks. I was surprised how much that bugged me so I figured there must be a way to highlight an entire line. It turns out this isn't a trivial thing to do. Syntax matches will only match to the final character in the line ($), not the width of the screen. No amount of tweaking a colorscheme would allow highlighting all the way across.After a lot of digging around, I found out about signs. This is a built-in feature which allows you to add a marker to a line for whatever purpose you want. It can point out debugging information or provide visual checkpoints to mark out things in your document. It's probably very handy but as I've only just started using vim, I don't really know what it's best for. However, as a side-effect, it can also apply a style to the entire screen-width of a line.
Some googling, hacking and probable violation of Vim plugin best-practice, I knocked together this plugin:
When this is installed, it will highlight any embedded CSS or JS blocks in a HTML, PHP, Velocity templates or Ruby files. Well, it will apply the syntax class 'HighlightedBlock' to the line. If your theme has a style for that, it will highlight it. Incidentally, I updated the Cobalt port to include that style.
It runs on initial load then refreshes every time you exit insert mode.
I might update it later to highlight PHP blocks in HTML or some other things like that but for my current purposes, it's finished.
Warning
- It pays no attention to existing signs. If you use them, you probably shouldn't use this. If you know of a simple way to group signs together to stop me messing with them, let me know.
- When signs are added to a file, an extra two-character column appears to the left of the line numbers. This plugin shrinks the line-numbers column by two characters if signs exist and increases it again when they are removed. This stops everything from jumping around but if you're working on a 10,000 line file, you might see some confusion down the bottom.
Installation
As with the Cobalt theme, if you're using Janus, add this to
~/.janus.rake, I still have no idea if this works. It might. :vim_plugin_task "HighlightBlock.vim", "git://github.com/thingsinjars/HighlightBlock.vim.git" -
Cobalt.vim
What?!
Another port of the TextMate theme 'Cobalt' to Vim?
But there are already so many!
Yes. Yes there are. However, the other ones I found were all missing something. Some had the right colours but in the wrong places, some had most of the right things highlighted but in slightly wrong colours. None of them had coloured the line-numbers. I think this is the most complete port. The initial work was done automatically using Coloration and then manually tweaked and added to. I know I should probably have just picked one of the existing GitHub projects, cloned it and pushed to it but I feel it would be a tad presumptuous of me to just turn up in someone's repository one day saying "yeah, you did alright but mine's better". Besides, I've never tried making a theme for Vim before. I've probably done something wrong (see below). If it continues to work for a while without causing any major issues, I might look at pushing it to another repo.
This was done on top of a vanilla install of the excellent Janus configuration of MacVim so whatever plugins are installed by default may have an affect on this.
There are a few limitations in the syntax files enabled by default so this includes a couple of matches, regions and things that really shouldn't be in a colorscheme file but I've included them because I felt like it and it was the only way to really match some of the highlighting TextMate allows (this is the thing I was referring to above).
I haven't really touched the NerdTree colouring much as it's probably impossible to have different background colours in different panes. Can't guarantee that, though.
Installation
There are probably some conventions to do with how to organise a GitHub project so that it can be automatically installed but I've just gone with sticking it in a directory called 'colors' so it can be pulled in from the root of your
~/.vimdirectory.If you're using Janus, add this to
~/.janus.rake, I think it'll work:vim_plugin_task "Cobalt.vim", "git://github.com/thingsinjars/Cobalt.vim.git"If you're not using Janus, you probably know what you're doing anyway.
The GitHub project is here:
Screenshots
The first of each pair is Vim, the second is the TextMate original.
Editing CSS
Editing HTML